
thoughts on OpenAI o3 model
On December 20th, OpenAI released o3 – second generation reasoning model. Here's why I think you should care about it.
~ François Chollet [source]
This post is based on two resources:
- original video announcement from OpenAI
- François Chollet's blog post on o3's score on the ARC-AGI benchmark
Chollet's blog post is the most interesting insight I found that shines new light onto the evaluation of the o3 model on the important general intelligence benchmark called ARC-AGI. Chollet made it a little bit technical, so I'll try to extract the essence of it into a more comprehensible form.
tl;dr
New o3 model from OpenAI is a breakthrough improvement over other models evaluated in the ARC-AGI benchmark (set of tasks the AI model has to solve in order to prove it has general intelligence). o3 is able to adapt to tasks it has never seen, and does so on nearly human-level.
Here are its results, compared with the other models.
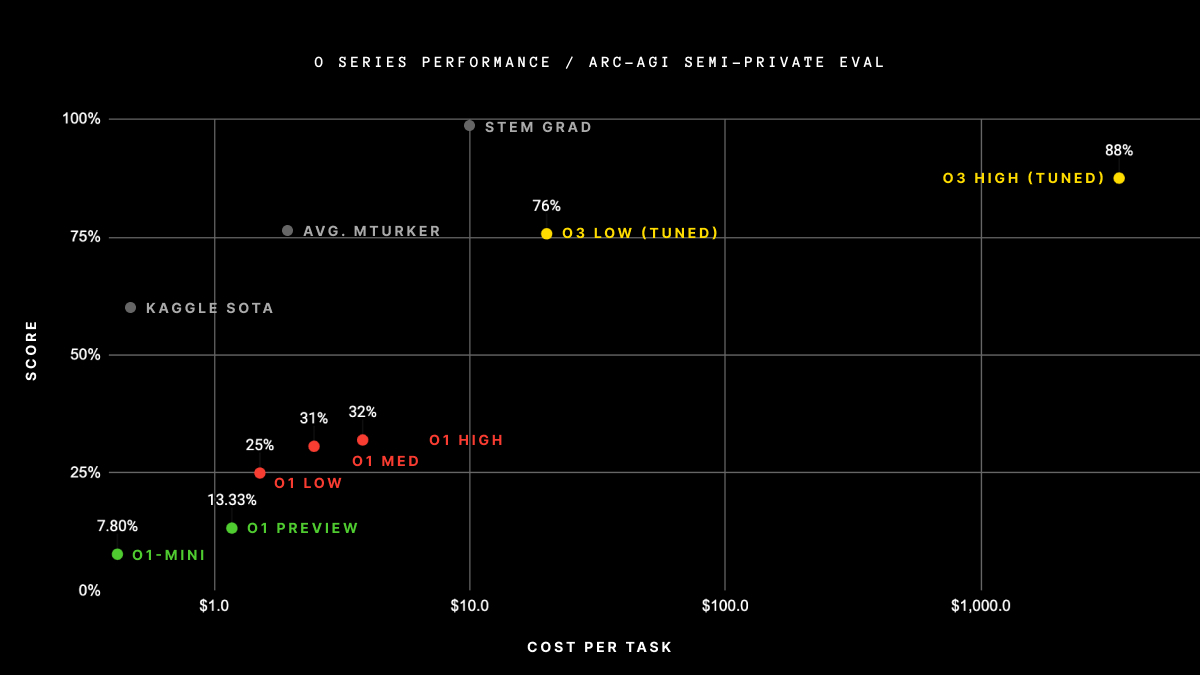
Source: ARC-AGI
A bunch of explanations:
- ARC-AGI semi-private eval - a set of 100 tasks the model is requested to solve. Here, 76% score of o3 low (tuned) means that it successfully solved 76 of these tasks.
- y axis shows the score a given model achieved on the ARC-AGI benchmark
- x axis shows how much, on average, it cost to solve the task by the model (counted as the compute/API cost).
- "KAGGLE SOTA" - the best model on the ARC Prize 2024 Kaggle competition
- "AVG. MTURKER" - average score of the human from Amazon Mechanical Turk's service evaluated on the ARC-AGI benchmark
- "STEM GRAD" - score the graduate student from the STEM field get on the benchmark
- "LOW/MED/HIGH" next to "o1" and "o3" scores - how hard the model is allowed to reason1 about the task it is presented with. This directly corresponds to the reasoning_effort parameter from the OpenAI's API.
- "TUNED" (next to o3 scores) - this is to denote that the o3 system has been trained on the ARC-AGI-1 Public Training set. Since it has some knowledge about the ARC-AGI data before the evaluation, it's considered to be tuned to the task.
I believe that even though o3 itself will not replace programmers, scientists, mathematicians, and others working in the STEM field, it definitely highlights the trend in the industry.
It seems we're entering the phase in which there will exist strong models that will achieve human, or maybe even superhuman performance on very specific tasks (like coding).
Is it good or maybe bad?
It is what it is, to be honest. What is important is to stay on top of all of that.
Are you afraid?
I am. But I don't want to let this fear and uncertainty paralyze me. What helps me in such situations is to better understand what I'm dealing with. That often shows that my fear is caused by misunderstanding the situation, not by the situation itself.
Let's understand the o3 then, even just a little bit of what it is and what it does.
What is o3?
Models like GPT struggle with tasks they haven't seen in the training data because they lack true reasoning abilities. Their answers are generated using the same amount of compute, no matter how complex the problem they're solving is. This doesn't make sense, at least not in the way we understand true intelligence and what it takes to solve the problems. This "one-size-fits-all" approach works well for familiar tasks but sparks issues when faced with something genuinely new, as it prevents GPTs from adapting to the unknowns.
Reasoning, on the other hand, involves breaking down a problem into smaller, manageable steps and exploring different solution paths. This is often called a chain of thought (CoT), where each step logically follows from the previous one, leading to a solution. GPTs were tricked to work this way by prompts like "think about it step by step", maybe you are familiar with this technique. It worked well, but had its limitations.
o1 before, and now o3 represent a breakthrough because they leverage this reasoning process by design. Unlike GPT, o3 dynamically generates and evaluates different solution paths (chains of thought) to find the best approach for a given task, guided by the internal "evaluator model", probably in a way DeepMind's AlphaZero does its Monte Carlo tree search. This ability to adapt its computational effort based on the problem's complexity, a core feature of o3, is a significant shift from the fixed computation of previous models, moving AI closer to more human-like reasoning.
Is o3 AGI? Chollet doesn't think so (and neither do I):
~ François Chollet [source]
What is ARC-AGI and why is it important?
It's easy for humans, but hard for AI.
~ François Chollet [source]
You can read more about it here, including trying some of the challenges yourself! I highly encourage you to do this! I bet you'll quickly understand that these are quite tricky, but still relatively easy for humans to grasp intuitively.
This benchmark is one of a few that still haven't saturated, meaning that there's still space for improvement.
ARC-AGI challenges o3 can NOT solve, can you?
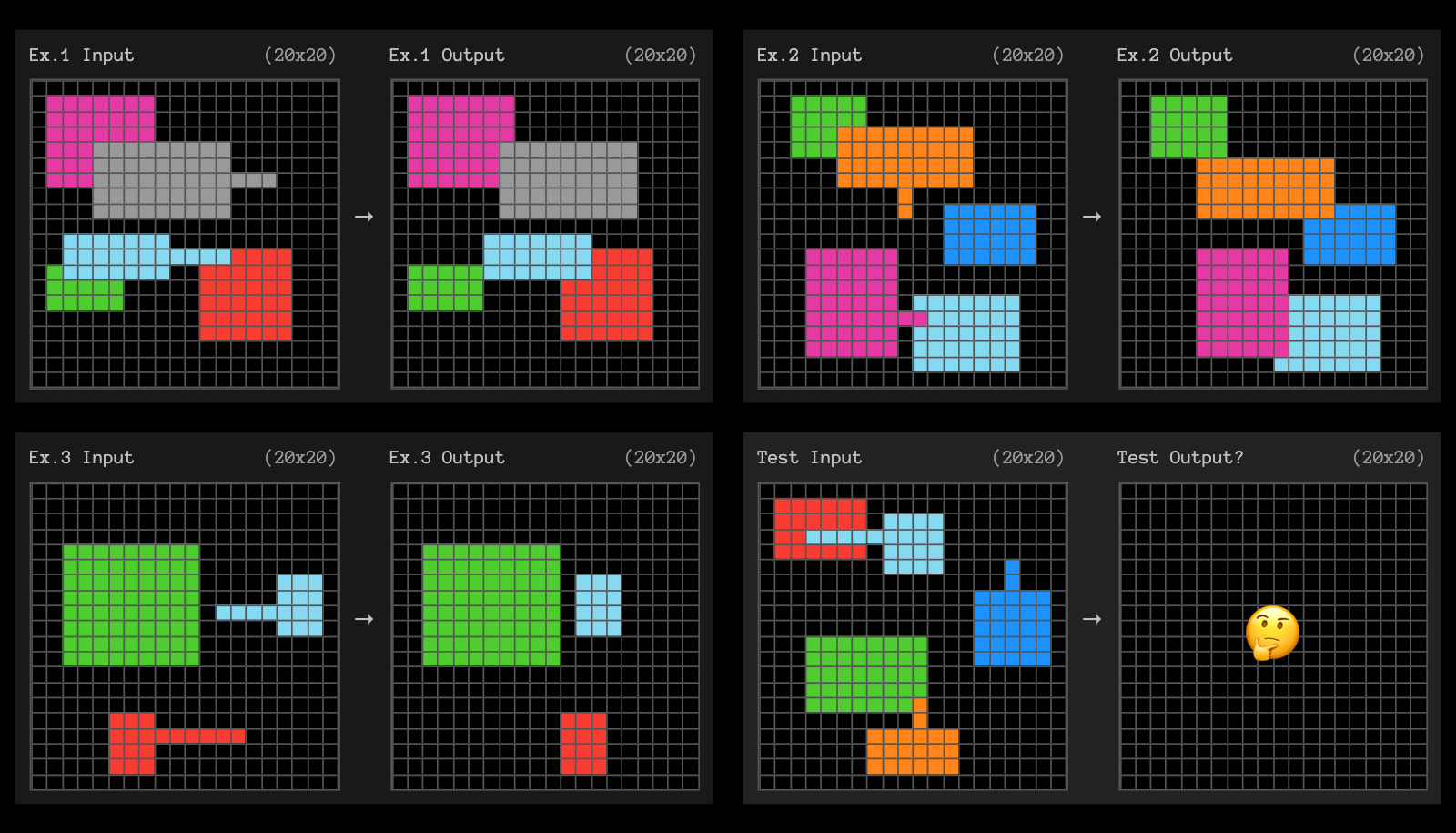
Source: ARC-AGI
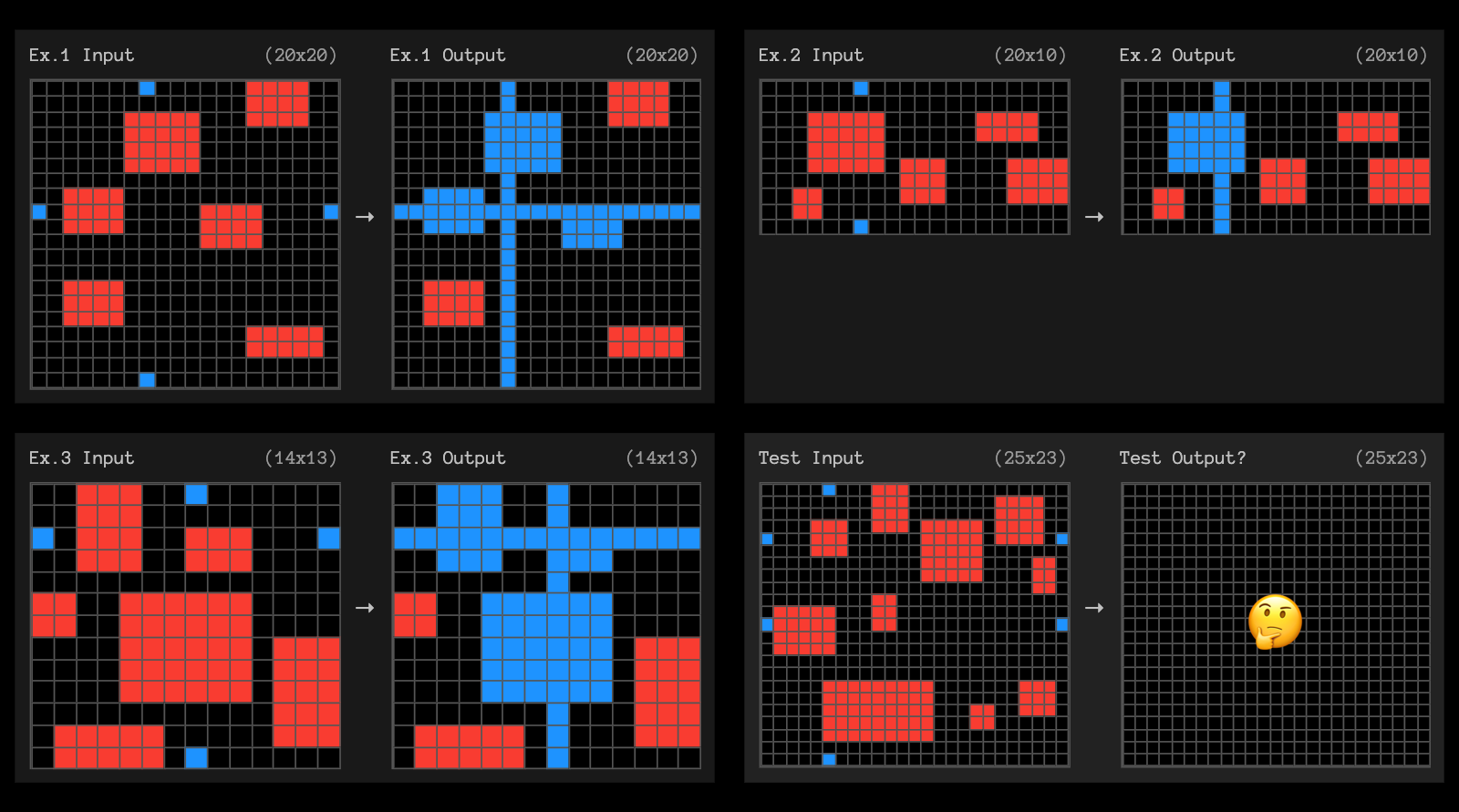
Source: ARC-AGI

Source: ARC-AGI
We're definitely living in the interesting times. I'm waiting with a bated breath for the next big thing. It's scary, but it's also fascinating.
Footnotes
- ↪ 1 "The o1 models introduce reasoning tokens. The models use these reasoning tokens to "think", breaking down their understanding of the prompt and considering multiple approaches to generating a response. After generating reasoning tokens, the model produces an answer as visible completion tokens, and discards the reasoning tokens from its context." Read more about it here.

